CS:APP Arch Lab记录
前置知识
Y86
esp - rsp 第三版CSAPP全部使用8Byte
Y86指令集对应Y86处理器,Sequential operation,每个周期执行一个完整的Y86指令,可以拆分出五个阶段,执行指令流水线(?数字电路的实现)
programmer-visible 程序员可见的状态,编译器 / 用汇编代码写程序的人,Y86与x86对应的寄存器结构是类似的,栈指针、传参、返回参数、条件码、PC。
Y86的汇编指令使用内存虚拟地址,由硬件和操作系统在读入程序时载入。状态码Stat 异常状态。
只有8字节的数据,称之为word 字,变长指令字,
addl, subl, andl, and xorl 对应 ZF, SF, and OF (zero, sign, and overflow)
HCL
硬件控制语言,从逻辑电路图到硬件描述语言,Verilog 根据描述生成电路,high-level Language。Single Bit,高电平表示1,反之表示0,与或非门。基本的对象时逻辑电路,bool eq = (a && b) || (!a && !b) ,持续响应输入的变化。
出于简单,每个字集都视为int,有 bool Eq = (A == B)。
基于设计的存储网络,决定各个存储设备值的组合电路逻辑。
硬件基础
组合电路,不需要时序信息,参考三极管等原件的特性,输入改变自然输出改变。若要生成有顺序的时序电路,需要引入时钟。
时钟寄存器(区分机器级编程提到的寄存器文件),只有在时钟上升沿才会改变自身的输出,就可以确保数据之间读取改变的先后顺序。
随机访问存储器(内存+寄存器文件);在读取时等价于组合电路,只需要输入改变(寻址改变)输出随之改变(对应寄存器的值); 在写入时则不同,由一个时钟控制。因此只读存储器,如指令存储器可以看作组合电路。

6类操作
- Fetch icode(指令代码) + ifun(指令功能 指导ALU) + (rA rB reg) + valp(顺序计算Increment)
- Decode 等价组合逻辑电路 读出ALU A ALU B
- Execute ALU运算(参考ifun),设置条件码(condition code register (CC)),ifun给出传送条件
- Memory 写/读 valM
- Write Back 写回存储器
- 更新PC
单个周期内,Y86-64的指令集不会读出现过写的状态。在时钟下,Input PC改变,当组合电路稳定之后,因为只取决于上一阶段的值,可以确保同时进行。(写操作需要另外的时钟,这里简化讨论)
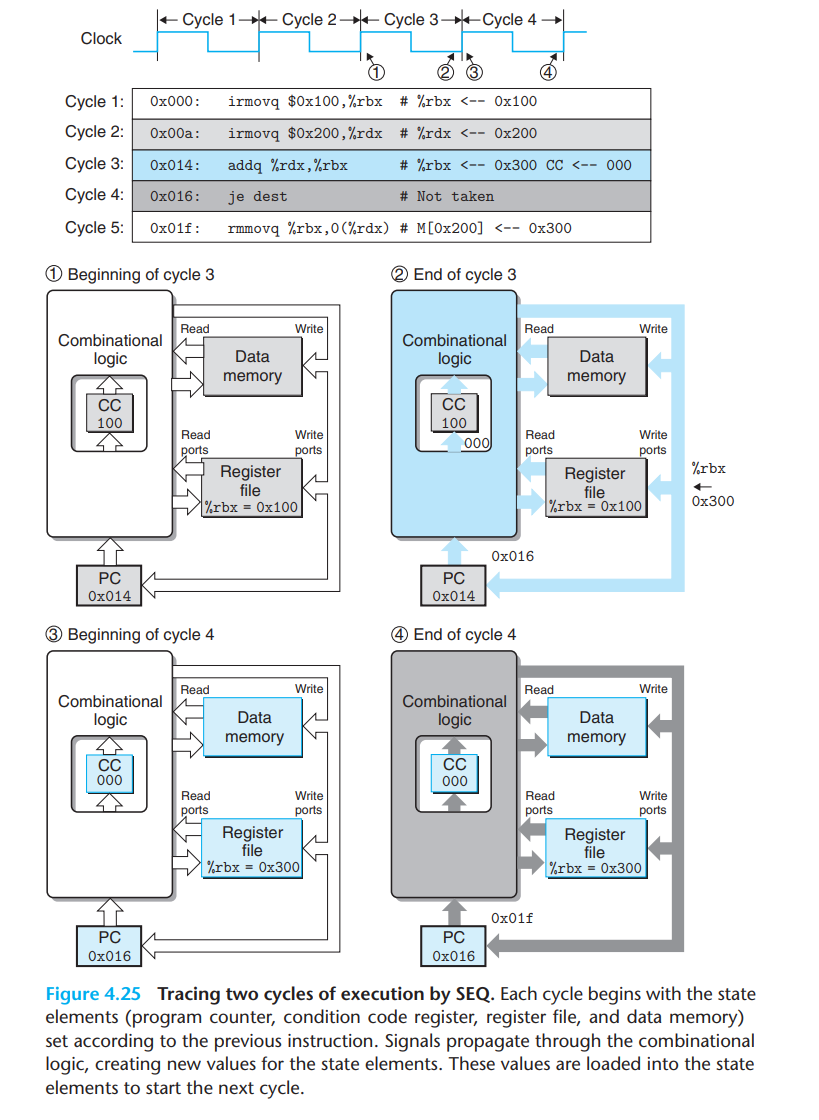
具体而言:
对条件转移,不会有运算设置完条件码后,直接读取条件码。只有运算后,才另外判断jmp。
对pushq而言,并不能rsp-8后直接M(rsp),而应该使用rsp-8得到的valE,直接M(valE)(同时写入rsp)。
Pipeline
使用流水线操作,借助时钟使得上个Stage结束的同时,下个Stage正好开始即可(选择每个Stage最长的时间,就可以只用一个统一的时钟。

比较Seq结构与Pipe结构,虽然单个指令的执行时间甚至更长,但可以同时运行至多三个指令,使得整体的吞吐量更大。流水线需要每个组合逻辑的耗时相同,长链条也使得更有效率的设计更困难(Nonuniform Partitioning)流水线链条越长,需要处理的冲突越多,寄存器用于等待的时间也越长(Diminishing Returns of Deep Pipelining)

Pipeline Hazard 数据冒险 控制冒险
Stall - 等价于动态生成所需数量的nop指令
Forward 数据旁路,可以处理寄存器写后读的问题,不能处理 load/use,读内存在写入阶段才得到操作数。后者依旧使用Stall(load interlock)。
控制冒险,在得到准确的跳转PC前的所有阶段都应该插入nop
异常处理。
具体流程
Part A
汇编程序
定义出链表的结构
1 | |
C语言传参与处理的汇编代码
main函数内定义
1 | |
1 | |
全局变量的定义
1 | |
1 | |
ys中都使用全局变量的方式,寻址的方式也较为简单
注意有INIT的过程,需要手动声明栈大小等。
1 | |
结果
1 | |
1 | |
结果:
1 | |
1 | |
结果
1 | |
Part B
只需要在固定的结构中加入操作码即可。
1 | |
Part C
F - D - E - M - W
对其中设计的存储设备的值的逻辑进行设计。
基本的流水线操作:Average CPE 15.18
可以优化的结构:
Prediction
1 | |
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!