CS:APP Cache Lab记录
前置知识
多级缓存
本质是基于代码运行时的时间局部性与空间局部性,往往顺序取指令,顺序访问内存中的元素,一段时间内选择的内存区域也往往相同。
具体流程
Part A
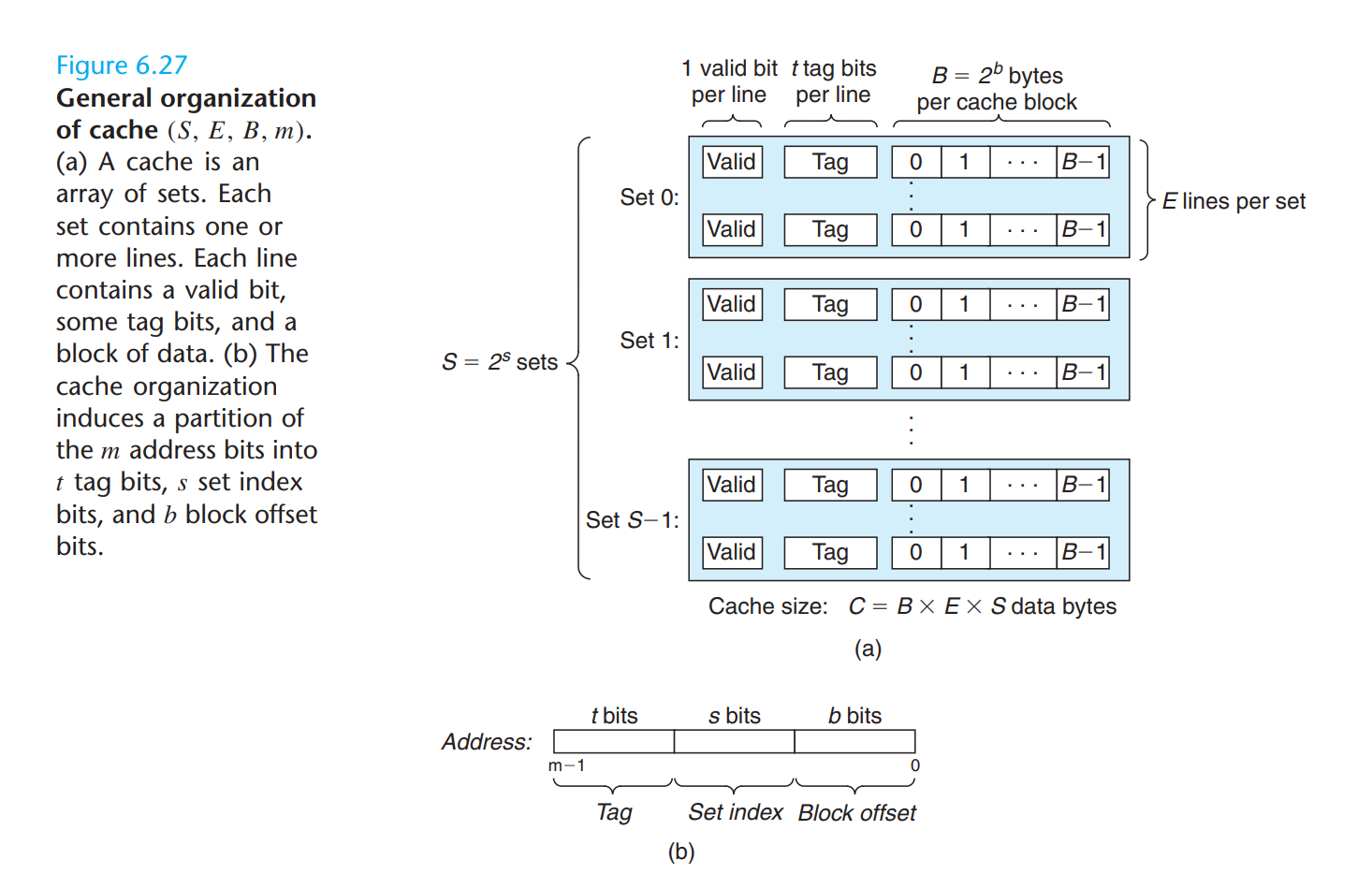
在c语言的文件中模拟出以上结构的二级缓存。该实验只模拟数据Cache,因此忽视I开头的请求,只需要考虑L load,读取数据;S store 存储数据;M modify load 后 store。-v不必要但有助于debug
提取参数
需要有两个可选择的功能,四个必要的参数。若缺少参数时需要打印Usage、option,只要含有-h 只打印帮助。
1 | |
1 | |
LRU实现
记录每组的最后遍历时间,O(n^2),冗余的堆可以降低时间复杂度到 O(nlogn), 到达的一定在最右侧,替换的在最左侧,冗余的队列也可以将时间复杂度降低到O(n),到空间复杂度也是O(n)。
也可以利用哈希表直接定位,然后借助双端队列达到O(n),可以保证空间严格在O(capacity)。
这里C直接使用基本的数据结构(没有哈希表)
注意用unsigned int, 参数过多...
1 | |
主体的solve函数,注意代码命名的规范。
1 | |
注意make函数-std=c99会报错,且printSummary 不需要重复定义。
Part B
32个组,里面包含8个INT。
try1
首先尝试分块,不能假定数组每一块所处的Cache,但相邻块位于不同的Cache。
1 | |
结果
1 | |
可以分开考虑,分开优化。可以看到具体的hit / miss。
?理论 8 * 8 块中一定会有6次Hit,考虑B的第一行 MISS MISS HIT ... ,B的第二行 MISS MISS MISS HIT ..., B的第三行 MISS HIT MISS MISS HIT HIT ... 至多三个MISS,第一次没有遍历过,第二次被A占用,写入后可能仍被A占用,第三次重新占用A。因此对于B最坏的情况 8 * 8 中 MISS 3 * 8,而对于A而言 MISS ... 被B占用 MISS ... !!! 前提是A B的每一列属于不同的CACHE,若满足以上情况,则MISS数为 16 * 5 * 8 = 640 343 倒也合理,若64 * 64也满足则会降低到 640 * 4 = 2560 (MAX)
1 | |
try2
!平均每一块允许MISS的次数 1.17 32 * 32,1.27 64 * 64,因此被占用的次数只能是常数级别,8 * 8 的块可以 Miss 2次
思路一:改变分块的形状或不分块? 若要复用读入A中的元素,一定会导致读入B中的多块,而若要复用B中的多块,又需要读入A中的多块。
思路二:在 8 * 8 或 4 * 4 的内部块进行赋值的优化
把处于相同Cache的赋值放到最后,借助临时的变量传递。计算出当前列与当前Cache占用相同块的行号。映射出Cache号。参数较多都可以优化到小于12个,这里便于表示。
思路三:牺牲时间复杂度
一定需要读入8 * 8 的分块,意义不大。
1 | |
结果
1 | |
ans
没想到可以直接复制一行/一列 8个作为参数,计算Cache号数的方式也比较取巧。滥用参数的下场... 循环只占了3 - 4 个参数,只取决与嵌套的深度。核心的逻辑在于:
- 一次性 横向读入 A1 A2 A3 A4 纵向写入 B1 B2 B3 B4 (同时使得转移的过程中可以横向读入,这里B1 B2 B3 B4 可能因为与A1 A2 A3 A4的Cache冲突多Miss一次)
- 横向读入B1 暂存部分 (B1此时一定在Cache中),一次性纵向读入 A5 A6 A7 A8,读回到B1,同时读入B5,一定覆盖B1。(这里B1可能因为读入A5 A6 A7 A8 多MISS一次,A5 同理)
- 横向读入 A5 A6 A7 A8, 纵向写入 B5 B6 B7 B8。
- 能够最优的前提在于 A B不占用同一个Cache的情况。
1 | |
小结
代码习惯
Part A没有建立数据结构,导致函数传参的复杂。
Part B 设置了一些没必要的参数,以至于没意识到12个参数的意义在于可以复制一整列 / 行。
Cache替换
- 两个数组起始所占的Cache行号是否相同
- 二位数组不同行之间的Cache行号是否相同
- 每读入一个Cache块,能够做到的最少被占用的次数。
- 具体到二维数组的转置,在知道Cache块大小和Cache行数的情况下,可以做针对性的优化。
- 因此一般而言,设置大小适中的block有一定概率能够提高程序运行的速度。
- 以块的整个周期来分析平均MISS的次数,以此推断整体的MISS。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!