实验概述
基于帖子的代码与框架,通过python
numpy库构建基本的神经网络模型,在基本结构的基础上增加了mini-batch梯度下降,针对多标签问题,使用softmax作为输出层的激活函数,cross
entropy定义损失函数。
使用MNIST数据集检验建立的模型,设立合适的神经网络层数,batch个数,学习率,epoch等参数,限于算力,只尝试了较为小的模型,并通过训练测试准确率曲线观察训练效果。
基于官方文档的代码与框架,通过pytorch建立CNN模型,与简单神经网络做比对,观察效果。
基本神经网络
基本结构
1 2 3 4 5 6 7 8 9 10 "input_dim" : 784 , "output_dim" : 500 , "activation" : "relu" },"input_dim" : 500 , "output_dim" : 150 , "activation" : "relu" },"input_dim" : 150 , "output_dim" : 10 , "activation" : "softmax" },
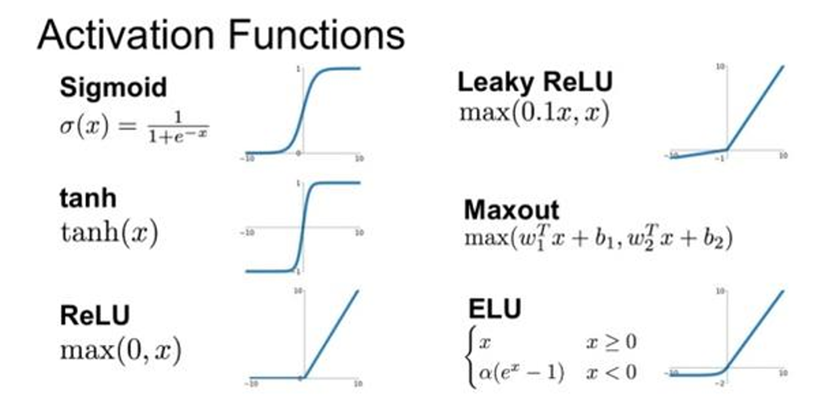
激活函数
激活函数为神经网络增添了非线性,能够拟合更复杂的模型。且选择合适的激活函数可以防止梯度爆炸与梯度消失,本文使用relu作为默认的激活函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def sigmoid (Z ):return 1 /(1 +np.exp(-Z))def relu (Z ):return np.maximum(0 ,Z)def sigmoid_backward (dA, Z ):return dA * sig * (1 - sig)def relu_backward (dA, Z ):True )0 ] = 0 return dZdef softmax (x ):max (x, axis=0 , keepdims=True ))return exp_x / np.sum (exp_x, axis=0 , keepdims=True )def softmax_backward (y_hat, y ):0 ]range (m), y.T] -= 1 return dx.T
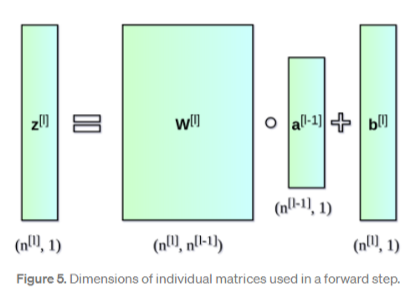
前向传播
设每一层的输出为\(a^l\) , 则有\(z^{l} = W^l \cdot a^{l - 1} + b^{l}, a^{l} =
g^{l}(z^{l})\) , 如下图所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 def single_layer_forward_propagation (A_prev, W_curr, b_curr, activation="relu" ):if activation == "relu" :elif activation == "sigmoid" :elif activation == "softmax" :else :raise Exception('Non-supported activation function' )return activation_func(Z_curr), Z_currdef full_forward_propagation (X, params_values, nn_architecture ):for idx, layer in enumerate (nn_architecture):1 "activation" ]"W" + str (layer_idx)]"b" + str (layer_idx)]"A" + str (idx)] = A_prev"Z" + str (layer_idx)] = Z_currreturn A_curr, memory
损失函数
定义损失函数,损失函数越小,代表预测值越精准,对于回归问题,可以使用RMSE作为损失函数,而对于分类问题,采用sigmoid
+
binary_cross_entropy的方式或log_softmax方式,考虑到softmax方法考虑到了每个元素之间的关系,在多标签问题有一定的优势,本文采用soft_max结合Cross_Entropy_Loss的方式。
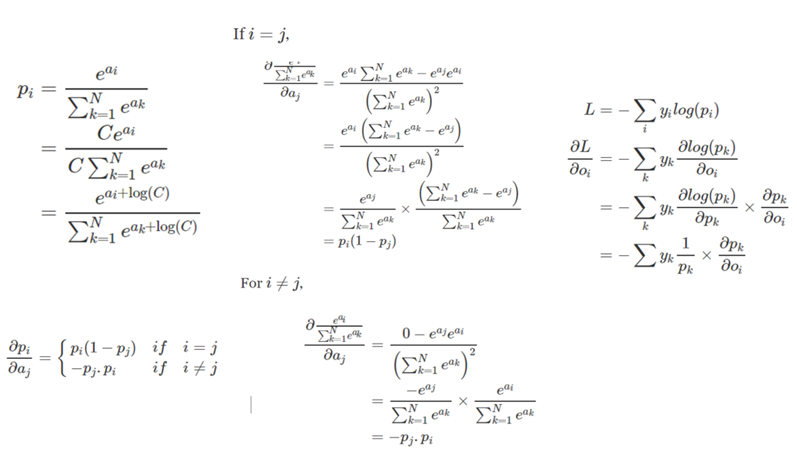
公式证明:
1 2 3 4 5 6 7 8 9 10 11 12 def softmax_backward (y_hat, y ):0 ]range (m), y.T] -= 1 return dx.Tdef cross_entropy_loss (y_hat,y ):0 ]range (m),y.T])sum (log_likelihood) / mreturn loss
pytorch则直接使用log_softmax + NLLLoss作为损失函数。
后向传播
通过梯度下降结合学习率更新值。 \[
x' = x - \alpha \frac{dy}{dx}
\]
示意图:
公式证明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def single_layer_backward_propagation (dA_curr, W_curr, b_curr, Z_curr, A_prev, activation="relu" ):1 ]if activation == "relu" :elif activation == "sigmoid" :elif activation == "softmax" :else :raise Exception('Non-supported activation function' )if (activation == "softmax" ):else :sum (dZ_curr, axis=1 , keepdims=True ) / mreturn dA_prev, dW_curr, db_currdef full_backward_propagation (Y_hat, Y, memory, params_values, nn_architecture ):0 ]for layer_idx_prev, layer in reversed (list (enumerate (nn_architecture))):1 "activation" ]"A" + str (layer_idx_prev)]"Z" + str (layer_idx_curr)]"W" + str (layer_idx_curr)]"b" + str (layer_idx_curr)]"dW" + str (layer_idx_curr)] = dW_curr"db" + str (layer_idx_curr)] = db_currreturn grads_values
训练方式
使用mini-batch训练,batch
size选择128,较SGD时间复杂度较小,较batch训练增加了random
shuffle,且多组训练,有助于寻找全局最优。
1 2 3 4 5 6 7 8 9 10 for i in range (epochs):0 ])0 128 while (start < train_data.shape[1 ]):
训练Mnist数据集
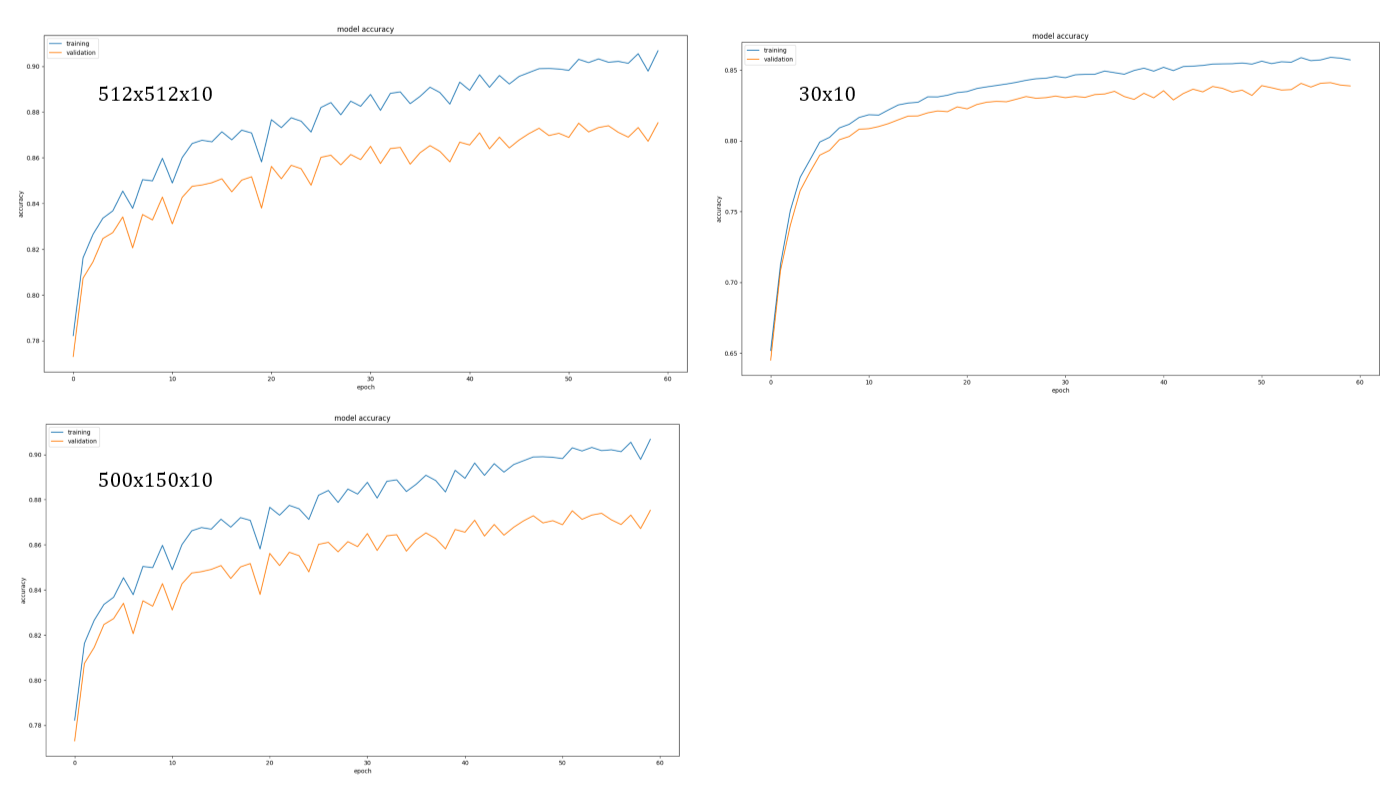
训练测试曲线
512x512x10
0.94
0.88
500x150x10
0.90
0.87
30x10
0.86
0.83
可以看出使用512x512x10的网络训练集与测试集的准确率相差较大,体现出过拟合的特点,500x150x10表现也较为相近。而30x10的网络训练和测试误差都较大,可以体现出欠拟合的特点。但整体网络的效果较差,由于针对图像数据,将图像的每个像素作为features,
并不能很好的体现图像的特点,而是用卷积神经网络可以解决这个问题。
使用CNN模型
参考,通过pytorch快速建立CNN模型,并设置droupout正则化防止过拟合。CNN模型通过卷积核更直观的展现图像各个区域的特点,且起到了降维的作用,而后面的全连接层则可将前面通过卷积抽象出的特征进行分类训练,较上文直接使用像素作为特征更有意义,准确率也更高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Net (nn.Module):def __init__ (self ):super (Net, self).__init__()1 , 32 , 3 , 1 )32 , 64 , 3 , 1 )0.25 )0.5 )9216 , 128 )128 , 10 )def forward (self, x ):2 )1 )1 )return output
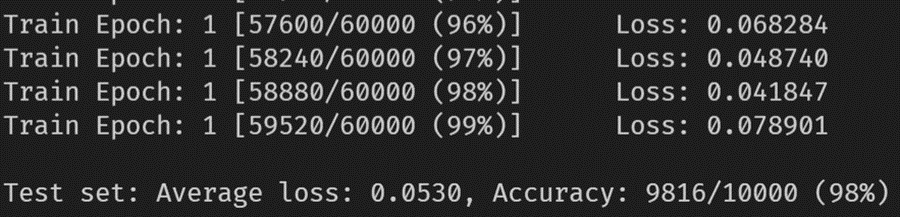
CNN训练结果
可以看出,只经过一个epoch就在测试集达到了98准确率,体现了CNN网络解决图像识别问题的能力。